AI property valuation refers to the application of artificial intelligence, such as machine learning and automated valuation models (AVMs), to determine the property value. AI analyzes vast sets of data including features of the property, like its location, condition, and number of rooms, and estimates property’s worth.
Property valuation AI capabilities include predicting property price for sale, lease, or evaluating the house price for rent and other investment. In our article, we delve into:
How Does an AI Valuation Process Usually Happen?
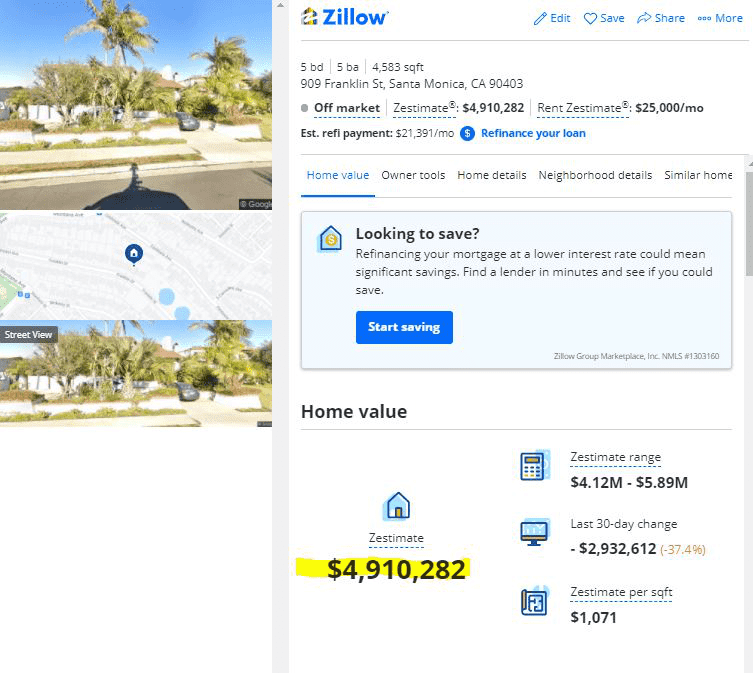
Zestimate, Zillow’s AI Real Estate Valuation Software | Source: Zillow
AI real estate valuation process consists of several stages:
- Data input. The user inserts the information about their property, such as the address, square footage, number of rooms, age, type, and others into the tool.
- Data collection and analysis. The AI model, trained to evaluate the parameters entered by the user and analyze how they influence property price, collects the data inserted previously. Afterward, the real estate appraisal technology identifies the correlations between the inserted parameters of the real estate valuation data set and the property prices, assessing the approximate property worth.
- Data output. When the data has been collected and analyzed, the system can provide an estimated property value to the user.
Some modern examples of AI in real estate valuation are Zillow’s Zestimate or Airbnb’s property valuation tool. Both of them are property marketplaces and both aim to inform landlords about potential sale or rental values while providing the same insights to buyers or tenants.
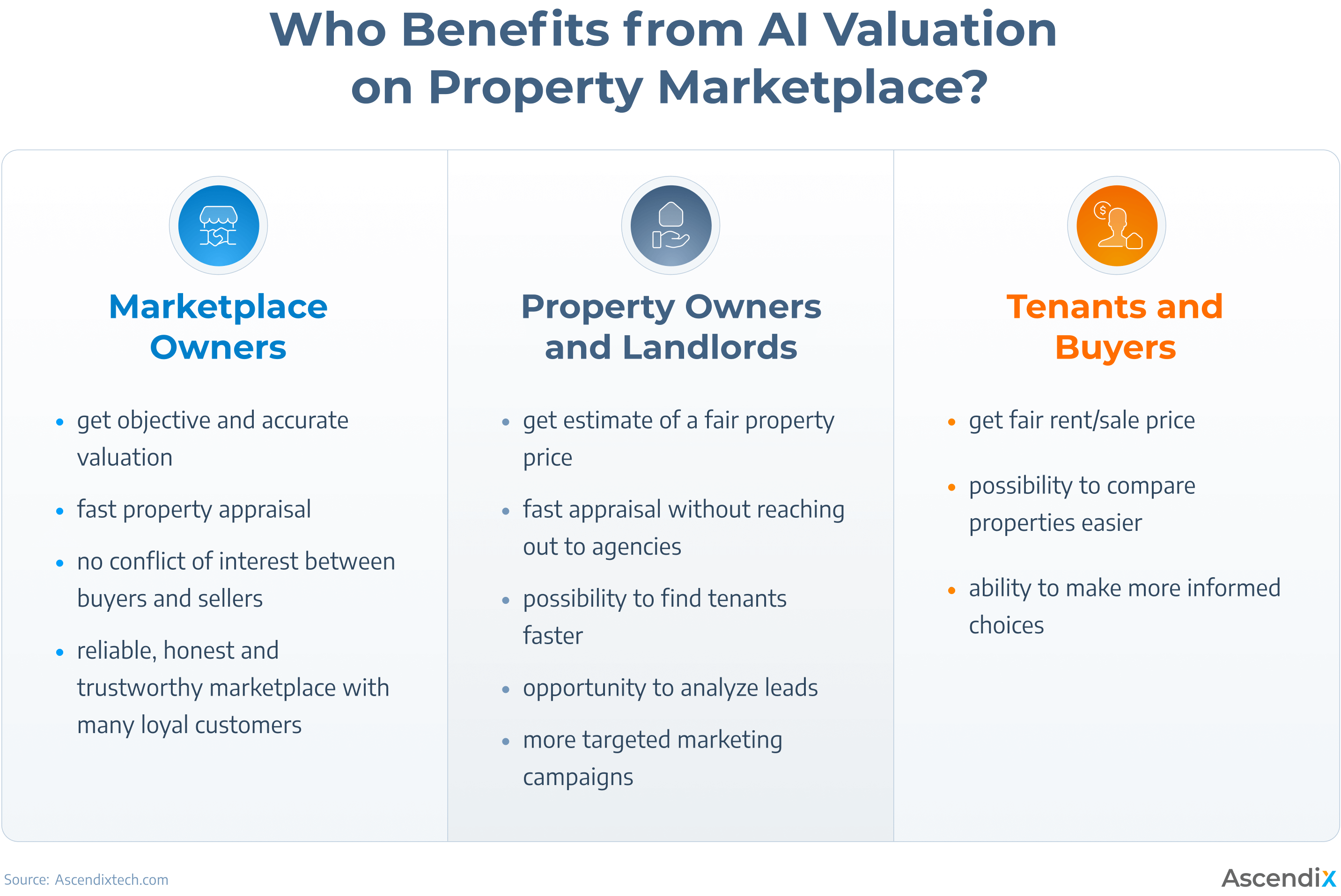
Who can benefit the most from AI real estate valuation?
- Real estate marketplace owners, who can leverage AI for automated property assessments across their platforms, handling both rental and sales property valuations.
- Real estate agents and brokers, who gain access to instant, accurate property valuations that help them price listings more accurately and way faster.
The same AI algorithm can be used to evaluate properties, whether for rental or sale purposes. The AI adapts to each scenario, using different data models trained specifically for rentals versus sales.
AI valuation has intuitive interface, where users enter property details and then get an estimate. However, behind the scenes, ML model analyzes market data, comparable properties, and local trends to generate the most accurate valuations.
As a result, you can make faster, more informed property decisions backed by comprehensive data analysis.
Why Does Every Property Marketplace Need AI Property Valuation Features?
AI property valuation provides all marketplace users with instant, data-driven price estimates that help both buyers and sellers make more informed decisions with precise and reliable data.
Automated valuations also make marketplaces more competitive in the market, since they provide transparency and reduce the time and cost associated with traditional manual appraisals.
- Marketplace owners who use AI real estate valuation provide objective, timely, and accurate property appraisals for all users of their marketplaces. Moreover, using AI means the elimination of possible conflicts of interest between buyers, who want the lower price, and property owners, who want to sell at a higher price. AI valuation bases its price assumptions on data, which does not take sides and represents an objective and unprejudiced point of view. This increases the reliability and trustworthiness of the marketplace, therefore enhancing user experience and customer loyalty.
- Property owners and landlords, who want to sell or let real estate, instantly get an estimate of the fair price. Machine learning real estate valuation technology saves their money for hiring real estate valuation agents while giving valuable insights into how much the property is worth. This also means the property would not stay empty for long, equaling even more saved finances and resources. Except for this, AI property valuation even gives the possibility to analyze the leads and generate more targeted marketing campaigns.
- Tenants and buyers are sure they get fair rent or sale prices while using AI valuation. Furthermore, AI gives them the ability to compare property prices with similar ones, which ensures a more transparent and high-level user experience.
Why Train Your Own AI Property Valuation Model?
Training your own AI property valuation model means getting superior data security, more accurate predictions using your actual marketplace data, and complete customization to your specific property types and business needs—advantages you cannot achieve with off-the-shelf solutions.
- Data security. Training and developing your own AI real estate valuation tool ensures the highest level of security possible, eliminating the slightest possibility of your clients’ or business data being sold, stolen, or just accidentally leaked onto the world web. Sensitive data stays under your control within the boundaries of the business, and it is used securely and confidentially only by the parties who have been provided access to it. Moreover, Ascendix, as a software development company, has the security certification ISO 27001:2013, which means that the processes in our company, including both operational ones and software development, fit the standard and keep your data safe.
- Valid and reliable predictions. If the real data from your marketplace is used, it ensures the highest probability of the estimation to be accurate and reliable. Large datasets give the best predictions, however, for businesses that have a smaller database data enrichment can be conducted, to ensure that the model has enough data to learn from.
- Adapted to your needs. The model specifically trained for your marketplace would fit your marketplace best so that it would be possible to integrate unique features or data points that are relevant to your user base.
- Full control and accountability. Training your own model for machine learning real estate valuation means the tool will be fully adapted to the marketplace type: residential or commercial, rental or sale, short- or long-term stays, etc. Also, it gives the possibility to set your criteria for the properties being appraised and this way gain a unique competitive advantage.
The Process of Property Valuation AI Development: ML Model Training
The process of machine learning real estate valuation software development can be divided into two major stages: the data preparation stage and the model training stage. During the first stage, the real estate valuation data set is collected, prepared, analyzed, enriched, and processed for the training. During the second stage, the training itself happens, and the model is then thoroughly tested to ensure that the results match the expectations and that the tasks are completed properly. The whole process of AI real estate valuation is depicted in detail below.
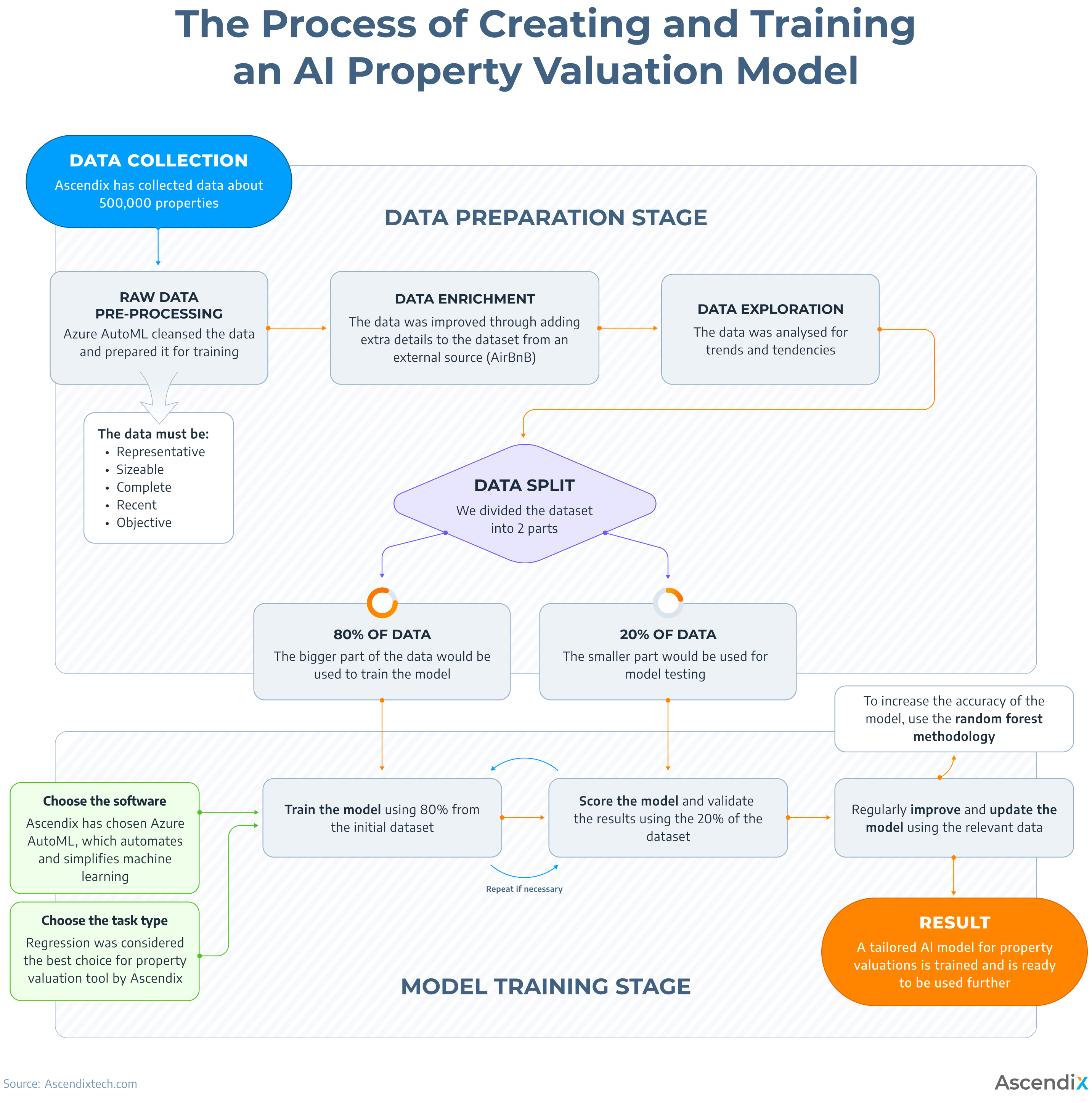
The Process of Creating and Training an AI Property Valuation Model
1. Data Collection and Pre-Processing
The journey begins with gathering raw real estate data. The raw real estate valuation data set may include information about property location, condition, age, and any other important features. The more data – the better, as the results of the training would be more accurate.
Ascendix used 500,000 properties to train the model, but everything depends on the business needs the real estate appraisal technology is meant to solve and the size of the available dataset. Before the data is fed to the model and training is started, the raw data must be processed and prepared for training. Therefore, data cleansing is performed at this stage, and the properties with many missing values are deleted. It can be performed automatically by the ML automation platform. For instance, Azure AI automatically does this for you after uploading the data.
Criteria for Training Dataset
For the machine learning real estate valuation model to work correctly, the training dataset must be representative, sizable, complete, recent, and free from biases to ensure model accuracy and generalizability.
Representative: the data must be representative of the actual real-world scenario where the model will be applied, i.e. for real estate valuation app would require information about certain property features and prices, and not the historical records of stock market changes.
Sizeable: the data must have enough volume for the model to learn from it and be able to generalize and make conclusions.
Complete: the data must be cleansed from missing values and empty features, as missing data can lead to biased or incorrect results because the model might make incorrect assumptions about the missing values.
Recent: the data must be as new and relevant as possible to ensure that the results of the valuation are correct and up-to-date.
Objective: the model must be unbiased and free from prejudice to exclude the risk of human factors interfering with the results.
2. Data Enrichment
Data enrichment refers to the process of improving the data quality in machine learning real estate processes aimed at enhancing the performance of models trained with this data. Data enrichment helps balance available data, adding extra features to improve the quality of the model’s training process and results. By introducing variations in the data, enrichment can help prevent models from overfitting to the training set. This way, the results become more relevant and accurate.
In the case of AI real estate valuation software, data enrichment can include adding demographic data, economic indicators, or urban development plans, providing a more holistic view of the valuation model. Moreover, if the company does not have enough available data for conducting AI appraisals model training, the dataset can be enriched with the help of another platform’s database, for instance, Airbnb or Zillow.
3. Data Exploration and Analysis
This phase involves analyzing the data to identify trends, patterns, and anomalies using statistical methods and visualizations. Understanding the relationships between various factors influencing property values is crucial for forming hypotheses and guiding model development.
Data analysis could include identifying the range and distribution of values, understanding the type of data, and checking for gaps and inconsistencies, which could have occurred due to errors in data collection, or they could represent rare but important events.
Data exploration and analysis help to understand how different factors are related to each other. For instance, in machine learning real estate software training, we might want to understand how factors like location, size, age, and condition of the property influence its value. Understanding these relationships is crucial for training the model and improving the overall accuracy of predictions later.
4. Data Splitting
To ensure that the model is trained and validated properly, it is important to split the real estate valuation data set into separate parts for training and testing. The typical ratio of the split is 80/20, but this can vary depending on the circumstances and purpose. The main principle is to have a large enough training set to allow the model to learn effectively, while also having a substantial test set to validate the model’s performance by using unseen data. This way, machine learning real estate technology is accurate and can provide the best valuation results.
The training set, which comprises 80% of the data in our case, is used to train the model. Using it, the artificial intelligence real estate appraisal technology learns to make predictions by adjusting its parameters based on the input features and the target variable in the training set.
The test set – the remaining 20% of the data – is used to evaluate the model’s performance. This set is not used during the AI real estate valuation model training phase and due to this, it provides a measure of how well the model can generalize new unseen data.
Data splitting is an essential step in machine learning, as it helps to conclude whether the results are valid or not by comparing the results model shows after the training to the actual data.
5. Development of an Artificial Intelligence Real Estate Appraisal Model
Choose the Software
As the data is collected, cleansed, enriched, and prepared, it’s time to start developing the machine learning model itself. To do so, it is necessary to choose the software which would handle the task. As the technologies used for machine learning real estate valuation become more widespread, the choice range extends, as there are multiple tools and platforms where the model training can be performed. Some examples are:
- TensorFlow is a popular platform and framework for machine learning. It offers flexibility and extensive support, particularly suitable for custom deep learning models and complex neural network architectures.
- Azure AutoML can handle a wide range of machine learning tasks, especially the ones related to the machine learning pipeline. It’s suitable for tasks like classification, regression, and time-series forecasting. It’s also especially useful for situations when it is unclear which algorithm is best to use, as Azure AutoML automatically selects the best one based on the data. This was the choice of Ascendix while building our custom real estate valuation software.
- Google Cloud AI, Amazon SageMaker, IBM Watson are comprehensive and versatile and therefore suitable for a wide range of tasks. They offer services for natural language processing, computer vision, speech recognition, and more. They also provide software solutions for deploying and managing machine learning models at scale.
- Scikit-learn is a good choice for traditional machine learning tasks that don’t require the computational power of deep learning, for instance, it will manage tasks like classification, regression, clustering, and dimensionality reduction easily.
- H2O.ai is designed for speed and scalability, which makes it a good fit for large-scale machine-learning tasks. It supports a wide range of traditional machine learning algorithms and deep learning algorithms and is best for tasks that require fast execution and large dataset managing capabilities.
Choose the Task Type
Except for finding the software most suitable for your needs, it is important to understand what type of machine learning tasks you are going to perform. There is a wide variety of them, so in order to stay concise, let’s discuss the ones available in Azure AutoML, which was used by Ascendix to create our AI real estate valuation software.
- Regression. Regression in AI property valuation is a type of machine learning task that involves predicting numerical values like a house’s price and analyzing dependencies between features like size, location, and rooms. Ascendix chose a regression model of machine learning for real estate valuation software.
- Classification. Classification aims to recognize the data feature and categorize it into a certain class. Classification is employed in real estate appraisal technology to categorize properties, such as distinguishing between apartments and houses.
- Computer vision. Computer vision is used in machine learning for real estate to interpret and understand the visual world. For instance, in AI appraisals, computer vision can recognize the property type (residential or commercial), identify property features like a swimming pool or solar panels, and segment the image (like recognizing a garage for 2 or 3 cars).
- Time series forecasting. Time series forecasting is a technique to predict future values based on previously observed values. In real estate AI appraisals, forecasting may be utilized for analyzing market trends in a certain location and neighborhood to predict the price of the property, identify the possible future rent price, or predict future market movements to find relevant properties for investment.
6. AI Valuations Model Validation and Testing
As everything is prepared, the chosen real estate valuation data set is inserted into the machine learning platform, relevant machine-learning tasks are chosen, and the training begins. The process is performed with AI trainers which teach the linear regression untrained model to recognize and analyze the interdependencies between data. During training, Azure Machine Learning creates a number of pipelines in parallel that try different algorithms and parameters.
After the algorithms were tried and the trainers finished the job, the model must be scored and validated. The trained model is used to make predictions on a new set of data, which was unseen by the model. In our case, it is the 20% test dataset, which was preserved after the initial data split. Using the metrics for scoring the models like MAE, RMSE, and R², the model training results are compared to the actual and real-life data, which ensures accuracy and reliability.
It is not uncommon, though, for the trained model to provide irrelevant results, or the training experiment to fail. In our case, a trainer failed 45% of jobs, which means the training process requires either more time or a more powerful environment to finish the job.
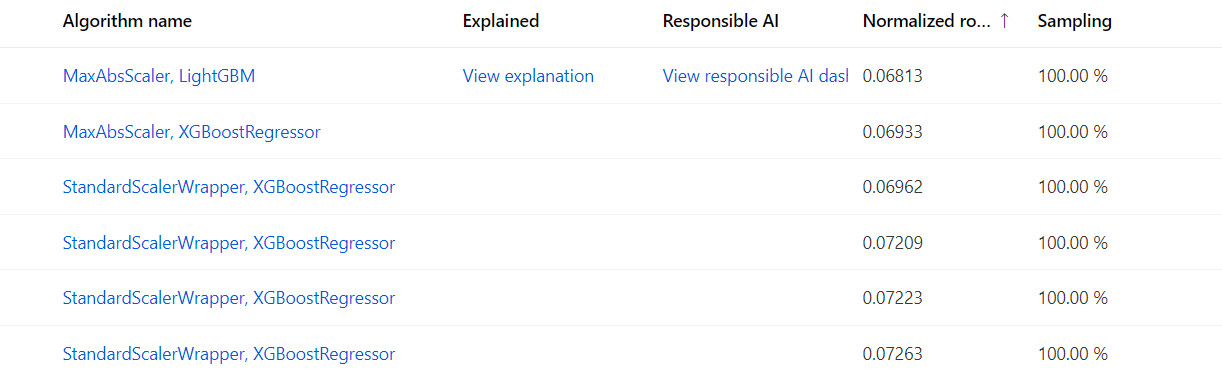
AI Valuation Software Model Trainers in Azure AutoML
When the experiment is successful, the results shown by the trained model (average predicted value) will be as close as possible to the Ideal value. In the case of the artificial intelligence real estate appraisal app by Ascendix, the results of the most successful experiment looked like the following diagram:
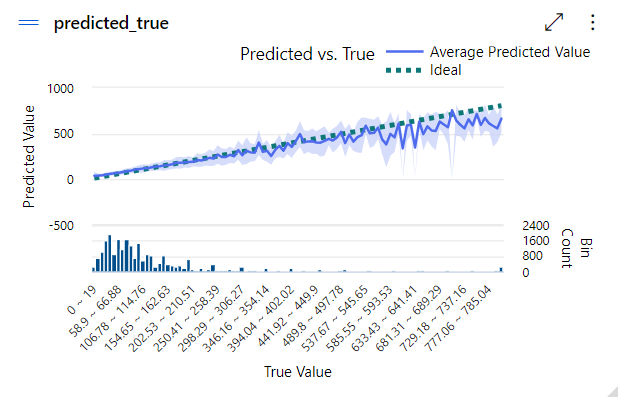
The AI Valuation Model Results Compared to the Ideal Performance
7. Model Updating and Improvement
To keep a model up-to-date, it’s important to regularly update it with new market data and make adjustments and improvements with the help of A/B testing. If the model isn’t working well, changes are made. This could involve choosing a different trainer, using different features, or even selecting a different model or dataset. After the required updates and changes are made and the model is working better, it’s then ready to be used with a new dataset. This process helps the model stay useful and adjust to changes in the market and data trends, which is required for high-quality machine learning real estate valuation.
8. Random Forest Methodology
To improve the model prediction accuracy, a method of random forest might be used, which ensures higher objectivity of the prediction, reduces the risk of bias, overfitting, and overall variance, and results in more precise predictions.
Random forest is a machine learning algorithm for regression and classification tasks. The main principle here is utilizing multiple algorithms and decision trees and combining them to get a single solution to the problem.
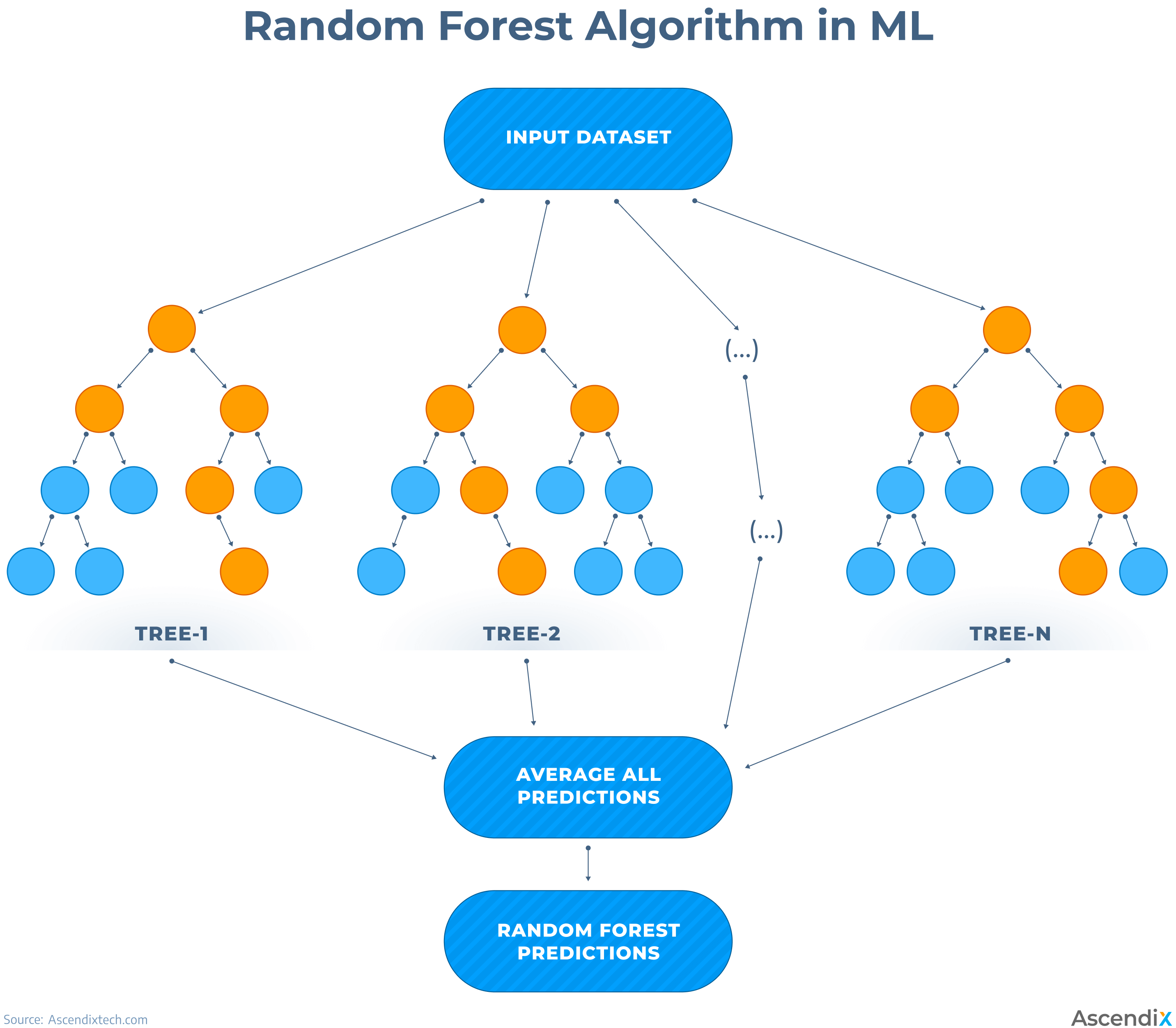
In machine learning terms, each decision tree is a simple model that makes a prediction based on the data it sees. The Random Forest algorithm creates a bunch of these trees, each one trained on a random set of data. When we need to make a prediction, each tree in the ‘forest’ makes its best guess based on the data it was trained on. Then, the results of all trees are analyzed, and the most common result is considered the best answer.
What Are the Challenges of Training Your Own AI Real Estate Valuation Software?
Training your own AI valuation model requires a lot of time (potentially weeks or months), high-quality property data (which smaller businesses may lack), significant financial resources for infrastructure and talent, and specialized expertise in both machine learning and real estate. Altogether, these challenges make training your own valuation model a hard task that demands careful consideration and cost-benefit analysis.
- Time. Training an AI model requires a significant amount of time. This includes not only the time for training itself, but also time for data collection, preprocessing, model design, and evaluation. The more complex the model is, the more time it will take to train. Additionally, the processes of fine-tuning, correcting, and optimizing the real estate machine learning model can also be quite time-consuming. If the trainers perform poorly, the process might need to start from scratch, and there is no guarantee it would be perfect. That’s why it is essential to hire a team with enough experience with machine learning. For example, one of the Ascendix experiments with creating and training a regression ML model took more than 3 days:

Time which was spent on launching a ML trainer
- Data quality. The quality of the data used for training significantly impacts the performance of an AI model. Poor quality data, like data missing details or too small dataset, can lead to inaccurate or biased results. Ensuring data is clean, relevant, and properly labeled might be a major challenge, especially for smaller businesses without a big dataset of properties for real estate AI appraisals.
- Expenses. Training an AI model can be quite an expensive endeavor. Costs may include data acquisition, computational resources like the environment for training and software or platform, and the human resources involved in designing, implementing, and maintaining the model. Therefore, the initial sum of investment for your own personally trained AI real estate valuation software will be substantial.
- Environment. Machine learning for real estate requires an environment powerful enough to handle multiple trainers, testing various models, and certainly huge amounts of data. That’s why setting up the right environment for AI model training can be challenging. This includes having the right hardware, software, managing memory usage, and handling all the potential issues with scalability and reproducibility.
- Qualified resources. Creating an AI real estate valuation software is a challenging task that requires huge expertise and significant experience in AI and ML. It also involves a lot of resources, which means you do not want to waste them by hiring cheaper professionals, as this would mean the investment would go down the drain. The ML team needs to understand both the technical aspects of model development and the business or research context in which the model will be used: real estate and proptech in the case of AI real estate valuation software. That is exactly what Ascendix can offer.
Ascendix for AI Real Estate Valuation Software Development
Ascendix is an AI and ML pioneer in the real estate industry, which combines a deep knowledge of modern technology with expertise in proptech and real estate. We have established unique and substantial experience in fostering transformative change in real estate.
Why choose Ascendix as your real estate partner?
- Extensive expertise in real estate technology. With more than two decades of experience, we have developed software solutions for big enterprises and small startups, delivering high-quality and tailored tools for real estate players.
- Collaborating with major players in the real estate industry. Companies like JLL entrust developing in-house solutions to us, together with more than 300 other clients worldwide.
- International outreach. With 5 offices around the globe, we outsource from Europe and work with the US market, which provides your business with a huge diversity of skills, being connected 24/7, and incorporating knowledge of international trends and demand into your solution.
How Ascendix can help in your AI real estate valuation:
- Consultancy. We can help you choose the most suitable AI solution for real estate valuation and appraisal, suitable for your business needs.
- AI Document Abstraction. We can integrate our AI intelligent document management framework into your existing software to simplify valuation paperwork management.
- Technical audit. The Ascendix team can perform the audit of your existing valuation tool, if you are using one, and improve it with the help of artificial intelligence or other features per your request.
- Custom software development. We can build a custom real estate AI valuation software for you.
- Integration of existing or custom solutions. If you have an existing solution in mind, that you would like to integrate into your software, we can do this for you, developing and optimizing all the features and customizing the solution for you.
In our further articles, we are going to share more details about custom training and development of your AI valuation tool. Subscribe to our newsletter and never miss a thing!

 (21 votes, average: 4.43 out of 5)
(21 votes, average: 4.43 out of 5)